serv00和 ct8主机一键安装哪吒探针和多主机保活 (五)
一、前言
前文 serv00和ct8主机一键安装哪吒探针和多主机保活(四) - TypeCodes 介绍了如何 utils.sh 脚本的使用方法,例如修改配置等等,那么这篇文章主要是介绍新增的哪吒面板数据库sqlite.db的备份功能。
项目地址:github.com/vfhky/serv00_ct8_nezha

前文 serv00和ct8主机一键安装哪吒探针和多主机保活(四) - TypeCodes 介绍了如何 utils.sh 脚本的使用方法,例如修改配置等等,那么这篇文章主要是介绍新增的哪吒面板数据库sqlite.db的备份功能。
项目地址:github.com/vfhky/serv00_ct8_nezha
前文 serv00和ct8主机一键安装哪吒探针和多主机保活(三) - TypeCodes 介绍了如何使用青龙面板进行保活,这一篇文章主要是介绍 https://github.com/vfhky/serv00_ct8_nezha 项目中的 utils.sh 脚本工具。

前文 serv00和ct8主机一键安装哪吒探针和多主机保活(二) - TypeCodes 介绍了 https://github.com/vfhky/serv00_ct8_nezha 项目的架构,这一篇文章主要是介绍如何使用青龙面板来调用项目监控进程和主机保活。
前文 serv00和ct8主机一键安装哪吒探针和多主机保活 - TypeCodes 介绍了 https://github.com/vfhky/serv00_ct8_nezha 项目的使用方法,这一篇文章简要通过两个流程图来说明一下整个项目的大体流程。
基于 serv00 和 ct8 这种配置较低的主机,比较适合用来做探针。目前还没发现能自动安装哪吒面板和 agent 客户端的脚本,以及多主机间动态保活,所以写了这个 github 项目: https://github.com/vfhky/serv00_ct8_nezha。
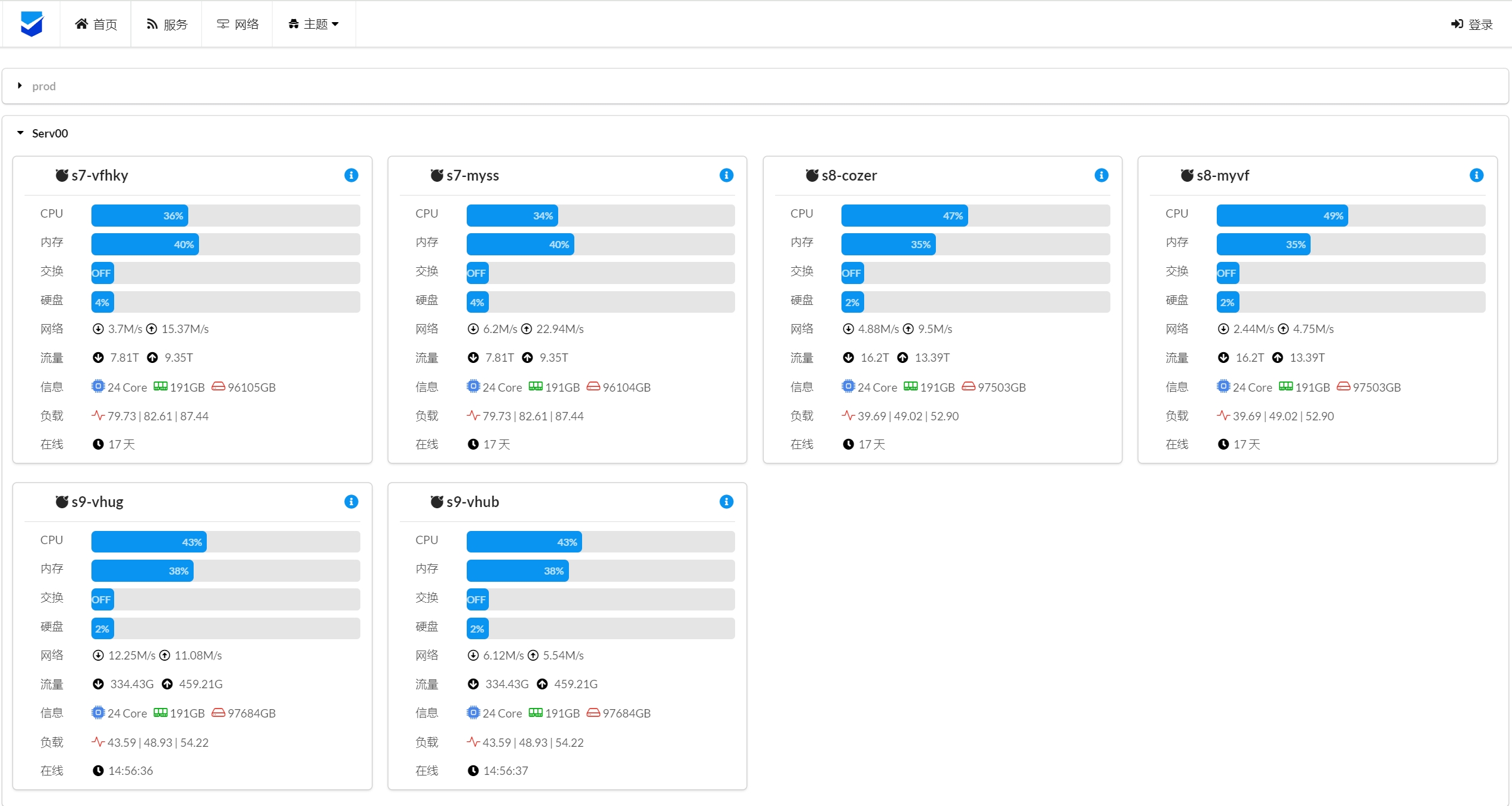
前段时间申请了 serv00 主机一直闲置没有用,但是这个主机的配置比较低(512 M 内存),所以准备用来装个工具类的小应用。
之前使用 Uptime Kuma 创建了一个比较全能的探针:web monitor ,看着哪吒探针使用量也比较大,于是选择在 server00 主机上安装了一下。
博客使用的是 pelican 开源静态博客系统,之前每次生成 html 代码都需要手动在服务器上用脚本生成的。也就是每次新增或者修改了文章都需要手工去执行脚本,然后发布到 nginx 目录。
鉴于每次的生成流程过于繁琐,所以最近考虑把博客的生成过程改用自动构建,同时在博客底部栏增加 git commit 和 自动构建 的信息。效果如下:
