博客基于 Astro 5,纯静态站点,所有页面在构建时生成,部署在 CDN 上。要在这样的站点里加入 AI 聊天,常见方案有三种:直接嵌一个通用聊天框、做一个 AI 博主分身、或者基于博客内容做 RAG 检索增强问答。
我选了第三种,但又不是只做第三种。

一、需求背景
TypeCodes 有 300 多篇跨 9 个技术方向的文章。读者的典型困扰是:「我想了解 Docker 网络,但不知道从哪篇看起。」现有的关键词搜索(/search)适合「我知道我在找啥」,但对模糊需求帮不上忙。
目标很明确:让 LLM 的通用推理能力和博客的独家内容产生化学反应。不是做一个通用聊天工具,读者要用 ChatGPT 会自己开。
二、三条路径的辨析与方案选型
头脑风暴阶段辨析了三条路径:
| 路径 | 说明 | 结论 |
|---|---|---|
| A(RAG 博客助手) | 基于检索到的文章片段回答,可溯源 | ✅ 主路径 |
| B(AI 博主分身) | 靠 persona 模仿博主口吻自由回答 | ⚠️ 娱乐彩蛋 |
| 通用聊天工具 | 直接调 ChatGPT,不做定制 | ❌ 拒绝 |
放弃通用聊天很简单:读者不是来博客找 ChatGPT 的。RAG 的价值在于「基于我写过的东西回答」,这是搜索引擎和通用 LLM 都给不了的信息增量。
B 模式的定位比较微妙。有人提议只做 A,彻底放弃 B。我保留了它,理由是博客不只是知识库,也有个人品牌属性。但 B 不承担严肃技术答疑,视觉风格上做了明显区分:紫蓝渐变背景、顶部常驻免责条、每条消息标注「AI 生成」。
形态设计上否决了「AB 并行两套系统」(维护成本翻倍),选了「一套 UI + Mode Toggle」:默认 A,B 是次要按钮。检索不到时 A 内部降级,明确告知「暂未找到相关内容」,不做成独立 mode。
| A 模式(问文章) | B 模式(闲聊) |
|---|---|
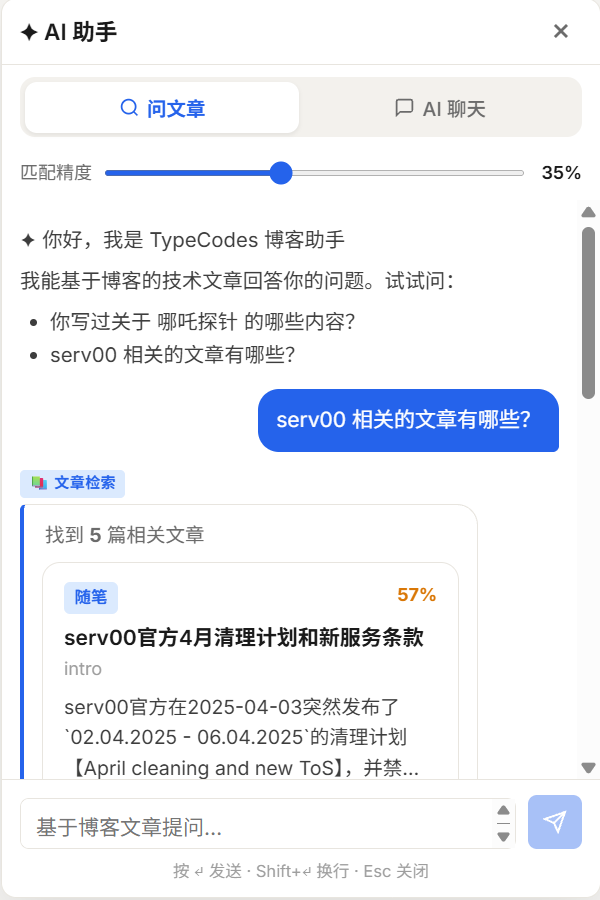 | 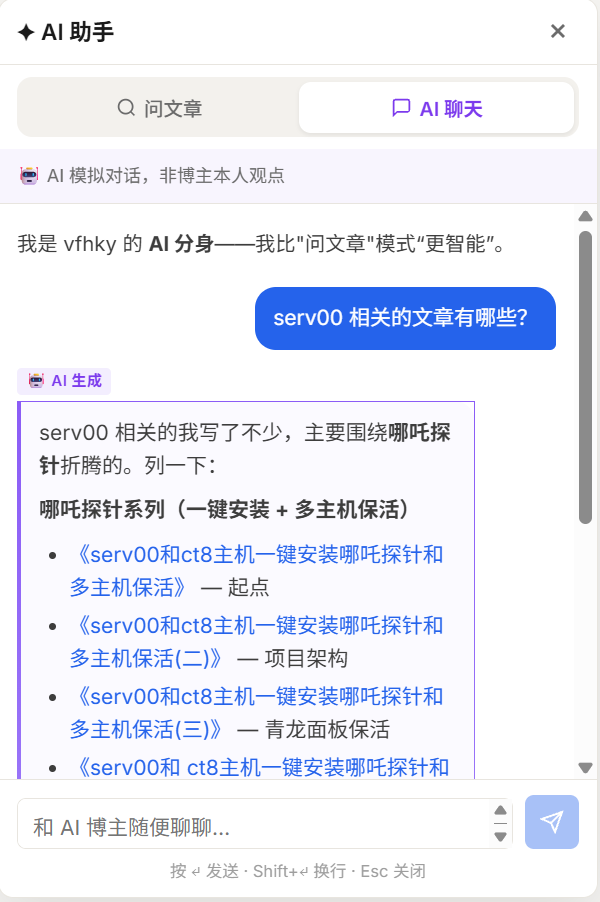 |
三、整体架构
架构分两层:构建期生成索引,运行期懒加载检索。
构建期
src/content/posts/**/*.md
│
├─ gray-matter 解析 frontmatter(draft: true 跳过)
├─ chunker.ts 按 Markdown 结构切片
│ ├─ H2 开启新 chunk
│ ├─ H3 达阈值时切分
│ ├─ 代码块整块保留
│ └─ 软限 800 / 硬限 1500 字符
│
├─ SHA-256 hash → 查 .cache/ai-embeddings.json
│ ├─ 命中 → 复用向量
│ └─ 未命中 → 批量调 cliproxyapi /v1/embeddings
│
└─ 输出
├─ public/ai-index.json (向量 + 元数据,~12 MB gzip)
└─ public/ai-posts.json (文章标题 + 摘要,B mode 用)运行期
浏览器
│
├── 页面加载:注入浮标 UI(~3 KB gzip)
├── 空闲时:预取 ai-posts.json
│
└── 点击浮标 → 打开面板(~40 KB gzip)
│
├── Mode A(问文章)
│ 1. 首次提问时懒加载 ai-index.json
│ 2. 问题 → Cloudflare Worker → cliproxyapi embeddings
│ 3. 本地余弦相似度 Top-5(同 slug 去重取最高)
│ 4. Top-1 < 0.35 → 降级提示「暂未找到相关内容」
│ 5. 拼 prompt → Worker → cliproxyapi chat (stream)
│ 6. 流式渲染 + 引用卡片(水平滚动)
│
└── Mode B(闲聊)
1. persona.md + 文章列表 → system prompt
2. Worker → cliproxyapi chat (stream)
3. 流式渲染,底部标注「AI 生成」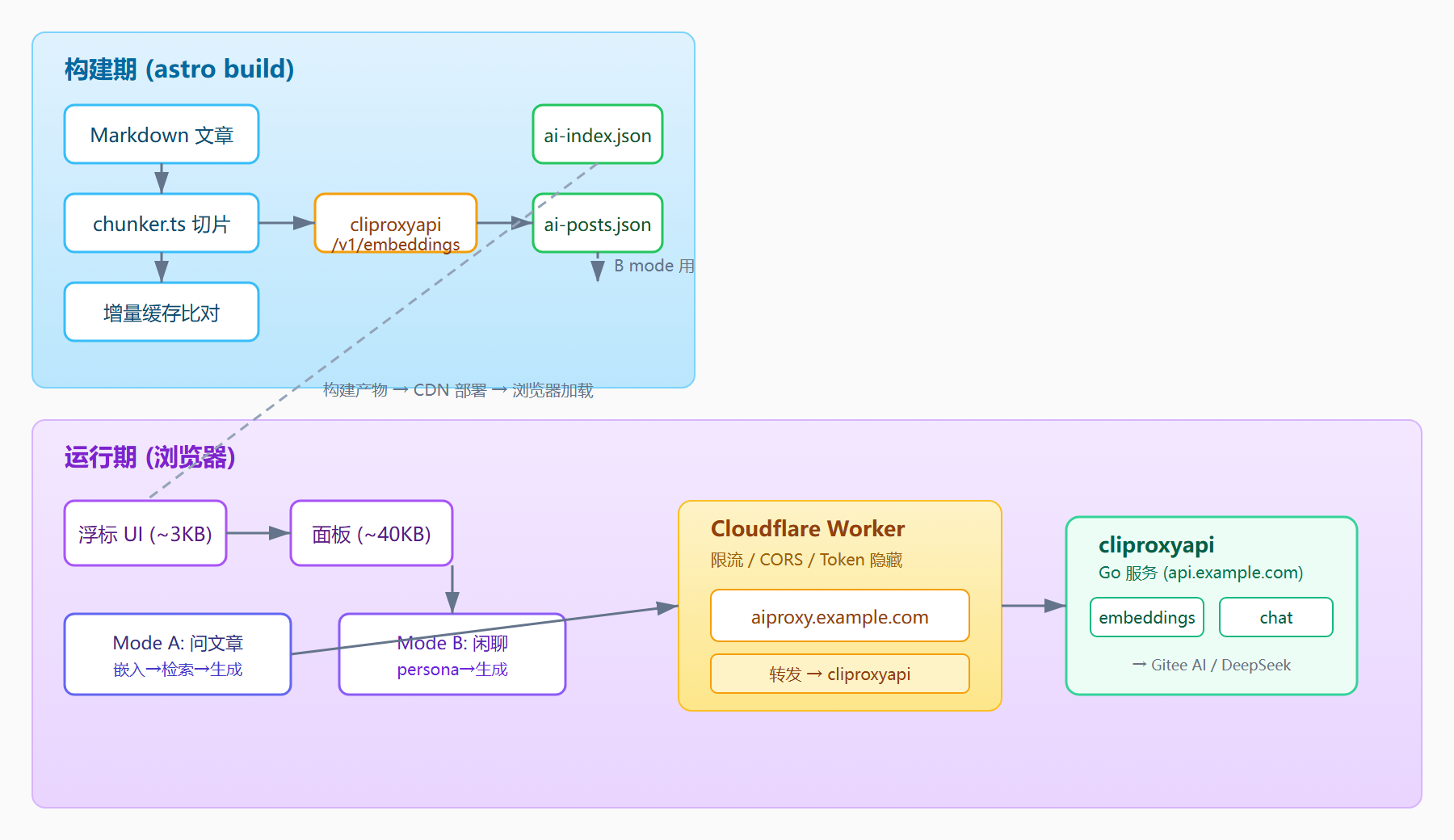
关键设计原则:纯函数层(chunker、retrieval、prompts)无 IO 独立可测;IO 层(cliproxy)不知道业务;业务层(client)编排上两层。构建期和运行期通过 ai-index.json 解耦,索引只入构建产物、不入 git。
四、Cloudflare Worker 代理层
前端不直接访问 cliproxyapi,而是通过 Cloudflare Worker 代理。Worker 地址配置在 .env.local:
PUBLIC_CLIPROXY_URL=https://aiproxy.example.com/v1加这一层有两个原因。
安全。前端 bundle 里写死 API key 和 base URL 有泄漏风险。Vite 的 PUBLIC_ 前缀变量虽然只在构建时替换,但最终仍会打进浏览器可读的 JS 里。Worker 代理隐藏了真实的 cliproxyapi 地址和主 token,前端只暴露 Worker URL 和 Worker 级别的受限凭证。
灵活。Worker 可以做请求限流、IP 黑名单、Origin 校验。后期换 embedding 提供商或聊天模型,只需改 Worker 配置,不需要重新构建前端。比如从 Gitee AI 的 Qwen3-Embedding-8B 切换到其他模型,改 Worker 转发规则即可,Astro 站点无感知。
这里有个关键的架构前提:cliproxyapi 本身已是聚合层,它后端接多个供应商池(Gitee AI、DeepSeek 等),Worker 再在前端和 cliproxyapi 之间加一层,形成「浏览器 → Worker → cliproxyapi → 供应商」的三层代理链。每一层只关心自己的职责边界。
五、纯前端检索的取舍
这是整个架构中最关键的决策。
一开始考虑过 faiss-wasm(浏览器端向量检索库),但它是 90MB 的 WASM 文件,加载一次就干掉所有性能预算。也想过 Pinecone / Milvus / pgvector,但意味着从「纯静态站」变成「有后端的站」,部署复杂度翻倍。
最终选了纯前端余弦相似度。3000-4500 个 chunk 的向量存在 public/ai-index.json 里,浏览器加载后本地算 Top-K。索引 gzip 后约 8-15 MB,4G 网络下 3 秒内加载完成。
代价是检索精度不如 HNSW,但对 3000 级别的数据量完全够用。索引体积随文章数线性增长,超 15 MB 时考虑降维或按分类分片。没有持久化缓存,每次打开面板重新加载索引。
换来的收益很直接:零后端、零数据库、零运维。检索完全在本地完成,隐私性好,不依赖任何第三方向量服务。
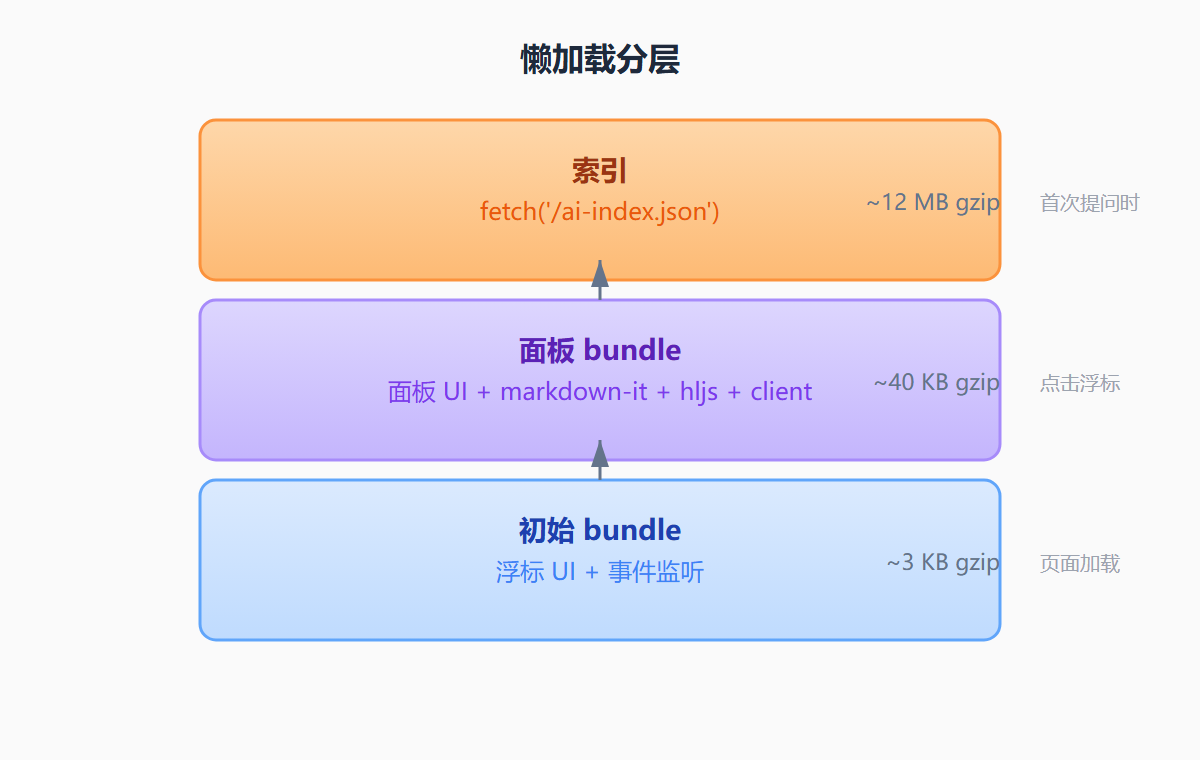
六、性能预算与懒加载分层
在纯静态站上加 AI 功能,最怕拖累首屏。定了几条硬性预算:
| 指标 | 预算 | 说明 |
|---|---|---|
| 首屏 LCP(面板未开) | 不劣化 | 面板未打开时完全不影响首屏 |
| 首屏 JS 增量 | ≤ 5 KB gzip | 浮标 UI + 事件监听约 3 KB |
| 面板 bundle 增量 | ≤ 40 KB gzip | markdown-it + hljs + client 约 40 KB |
| 索引 gzip 后大小 | ≤ 15 MB | 3000 chunk × 2048 维估算约 12-15 MB |
| 索引加载(4G) | ≤ 3s | 取决于网络状况 |
| A mode 首 token | ≤ 3s | 取决于 cliproxyapi 响应 |
懒加载分三层是关键:
初始 bundle: 浮标 UI + 事件监听 (~3 KB gzip)
↓ 点击浮标
面板 bundle: 面板 UI + markdown-it + hljs + client (~40 KB gzip)
↓ 发送第一条消息
索引: fetch('/ai-index.json') (~12 MB gzip)不打开面板,首屏完全不受影响。面板打开后才拉 40 KB 的代码。第一次提问时才加载索引。关闭面板后对话历史清空,无存留。
七、总结
这套方案在「纯静态架构不变」和「AI 能力可用」之间找平衡。RAG 提供信息增量,B 模式提供娱乐价值,Cloudflare Worker 代理解决安全问题,纯前端检索解决运维问题。构建期通过增量缓存实现秒级索引更新,运行期通过三层懒加载保证首屏不受拖累。在 300 篇博客这个量级上,这套架构是务实且合理的选择。
下一篇讲 Markdown 切片算法和增量缓存策略。
评论
评论加载中…